.svg)

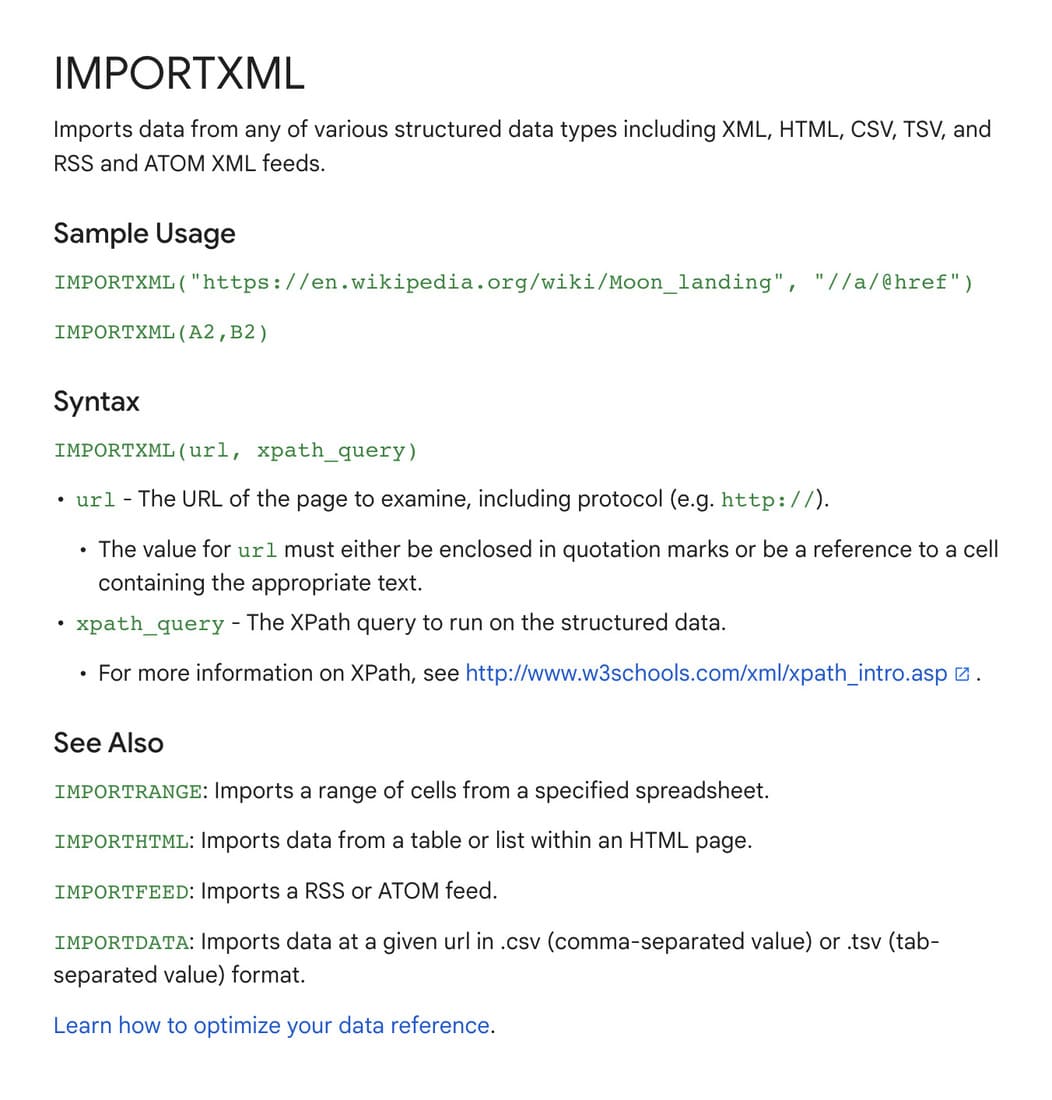
Qu'est-ce que la fonction IMPORTXML ?
La fonction IMPORTXML de Google Sheets révolutionne l'extraction de données web en permettant d'importer automatiquement des informations depuis diverses sources structurées. Elle prend en charge de multiples formats : XML, HTML, CSV, TSV ainsi que les flux RSS et ATOM.

Son principe de fonctionnement repose sur l'identification et l'extraction des données encadrées par des balises HTML (comme <balise> et </balise>). Cette capacité transforme n'importe quelle page web publique en source potentielle de données.
Les applications pratiques d'IMPORTXML sont nombreuses :
- Extraction massive de données : Capable de traiter 150 produits sur 15 pages simultanément
- Automatisation des tâches : Mise à jour automatique des bases de données
- Synchronisation : Maintien des informations à jour sans intervention manuelle
- Traitement de volumes importants : Gestion efficace des données volumineuses
- Intégration de flux : Connexion directe aux sources d'information XML

L'utilisation d'IMPORTXML, bien que puissante, nécessite une approche responsable. Plusieurs aspects légaux et éthiques doivent être considérés :
- Respect des conditions : Vérification systématique des règles du site source
- Limitation technique : Observation des quotas d'extraction autorisés
- Cadre commercial : Utilisation conforme aux licences et autorisations
- Protection des données : Respect des droits de propriété intellectuelle
Cette fonction transforme radicalement la collecte de données en la rendant accessible aux non-développeurs, tout en maintenant un haut niveau de performance et de fiabilité. Son utilisation stratégique, combinée au respect des bonnes pratiques, en fait un outil indispensable pour l'analyse et le traitement des données web.
LIRE PLUS : Liste d'outils pour collecter des données sur le Web
Bases Essentielles de l’URL et des Requêtes XPath avec IMPORTXML
Vous voulez collecter des données sur internet... rapidement ?
Peut-être voulez-vous copier un tableau à partir du site, ou peut-être voulez-vous récupérer rapidement des éléments SEO d'un concurrent.
IMPORTXML est là pour vous aider à automatiser vos opérations de collecte de données dans Google Sheets.
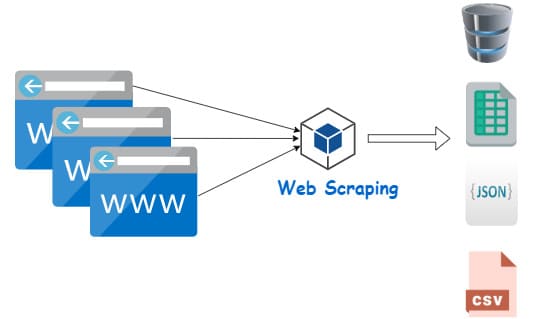
Les fonctionnalités d'importation de données disponibles dans Google Sheets, notamment à travers les fonctions IMPORTXML et IMPORTHTML, permettent d'importer facilement des données à partir de sites web directement dans les feuilles de calcul de Google, facilitant ainsi le traitement et l'analyse des données in Google.
La base d'une URL

- L'argument url est l'URL de la page Web à partir de laquelle vous souhaitez importer des données (data types),
- Indiquez le protocole (https:// ou http://).
- La valeur de l'URL doit être soit entre guillemets, soit être une référence à une cellule contenant le texte approprié.
La base d'une Requête XPath
Pour utiliser efficacement XPath, une compréhension solide des bases HTML s'avère indispensable. Les données web sont systématiquement affichées en HTML et stockées au format XML, qu'XPath interroge de manière structurée.

La force d'IMPORTXML réside dans sa flexibilité : chaque résultat de requête XPath occupe automatiquement sa propre ligne dans votre feuille de calcul, facilitant ainsi l'organisation des données extraites.
Les requêtes XPath essentielles pour le marketing digital :
- Navigation dans le contenu
- Extraire tous les liens : "//@href"
- Capturer le titre : "//title"
- Récupérer les H1 : "//h1"
- Éléments SEO critiques
- Meta description : "//meta[@name='description']/@content"
- Balise canonique : "//link[@rel='canonical']/@href"
- Directives robots : "//meta[@name='robots']/@content"
- Configuration hreflang : "//link[@rel='alternate']/@hreflang"
- Analyse approfondie des liens
- Liens internes : "//a[contains(@href, 'exemple.com')]/@href"
- Liens externes : "//a[not(contains(@href, 'example.com'))]/@href"
Pour maximiser l'efficacité d'IMPORTXML, l'analyse préalable du code source de votre page cible s'avère cruciale. Cette étape permet d'identifier précisément les éléments HTML pertinents et de construire des requêtes XPath adaptées. La personnalisation des arguments XPath en fonction de vos besoins spécifiques garantit une extraction optimale des données souhaitées.
Il existe quelques règles de base pour créer votre propre argument xpath_query :
La syntaxe XPath possède ses propres règles, disponibles dans de nombreuses ressources en ligne pour approfondir vos connaissances. Cette maîtrise technique transforme IMPORTXML en un outil puissant pour l'extraction automatisée de données web dans vos feuilles de calcul.
Guide étape par étape pour utiliser IMPORTXML dans Google Sheets
1. Commencez par ouvrir une nouvelle feuille Google
Tout d'abord, nous ouvrons un nouveau document Google Sheets vierge :
Pour cet exemple, vous pouvez utiliser la feuille d'exemple de Google Sheets :
Feuille d'exemple Google Sheets : Collecte de données avec ImportXML
2. Ajoutez le contenu que vous avez besoin d'extraire
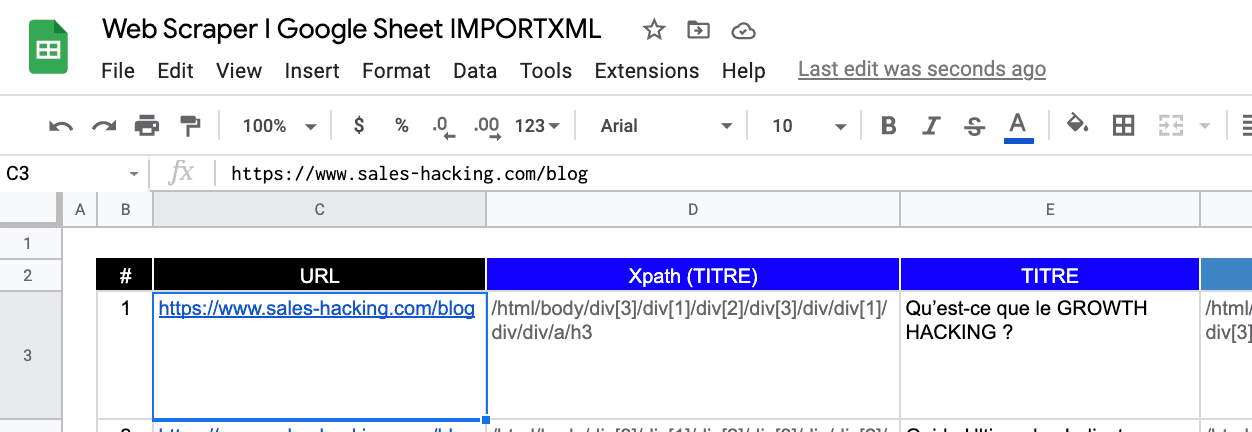
Ajoutez l'URL de la page (ou des pages) dont nous voulons extraire les informations du web.
Dans notre cas, nous allons extraire les titres de pages de l'ensemble des articles, ainsi que leurs URL et métadescriptions.
Notre URL de départ sera donc la suivante : https://www.sales-hacking.com/blog
3. Trouver le XPath
Utiliser l'inspecteur du Navigateur
Afin de trouver à quoi ressemble le XPath et comment le trouver simplement, il suffit d'utiliser un outil simple présent sur la totalité des navigateurs modernes : L'inspecteur.
Ce XPath va nous permettre de récupérer spécifiquement chaque information souhaitée sur la page de manière : :
- Relative : je souhaite tous les titres de blog de la page Web
- Spécifique : je ne souhaite que les 10 ou 30 premiers titres d'articles de la page Web ou 1 seul en particulier
Dans notre exemple, commençons par les titres des 30 derniers articles.
- Allez dans votre Navigateur préféré .
- Une fois que vous avez survolé le titre de l'un des articles, faites un clic droit
- Et sélectionnez Inspecter (Inspect en anglais)
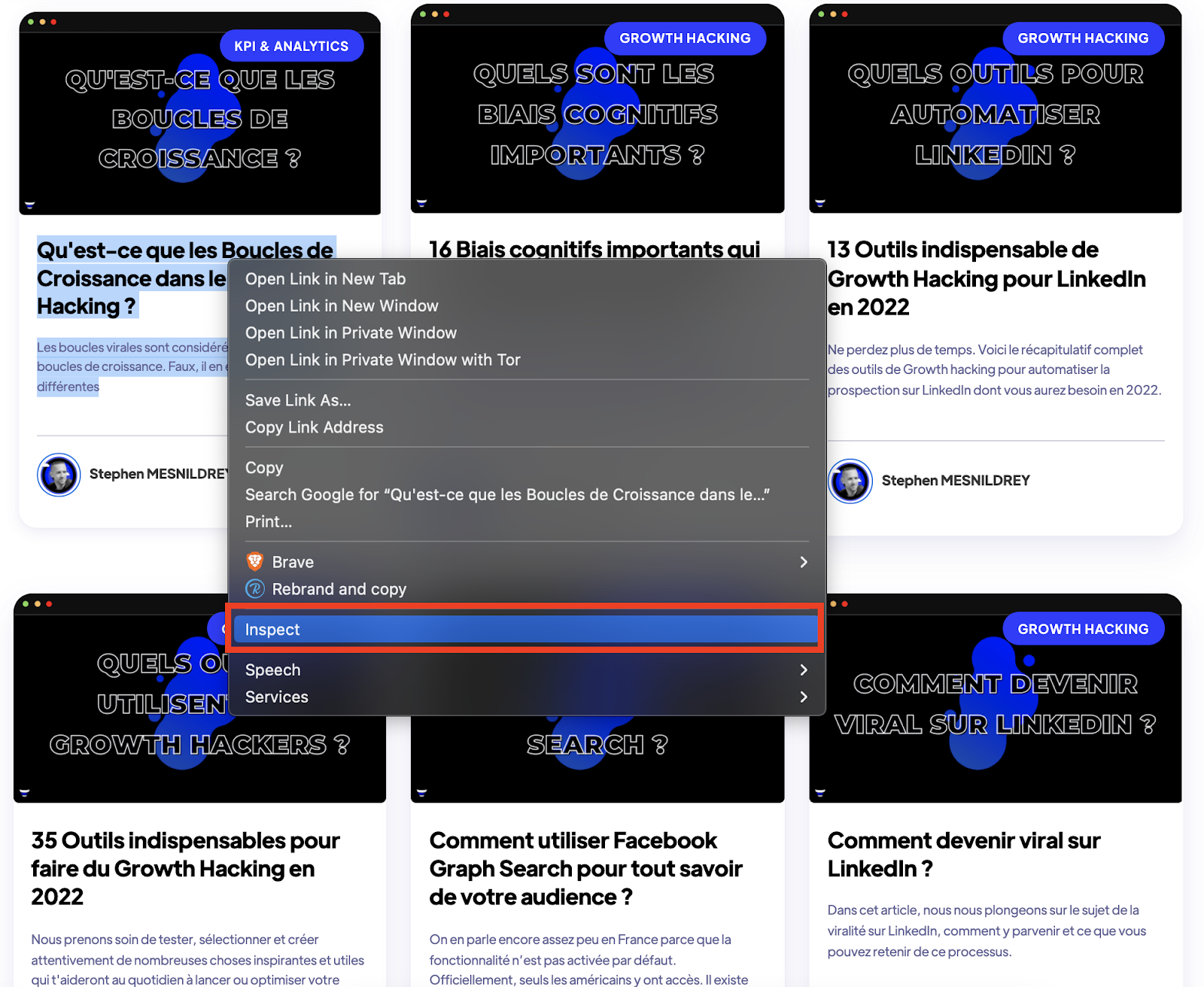
Une fois cliqué le Navigateur vous affichera le code HTML de la page Web comme ci-dessous :
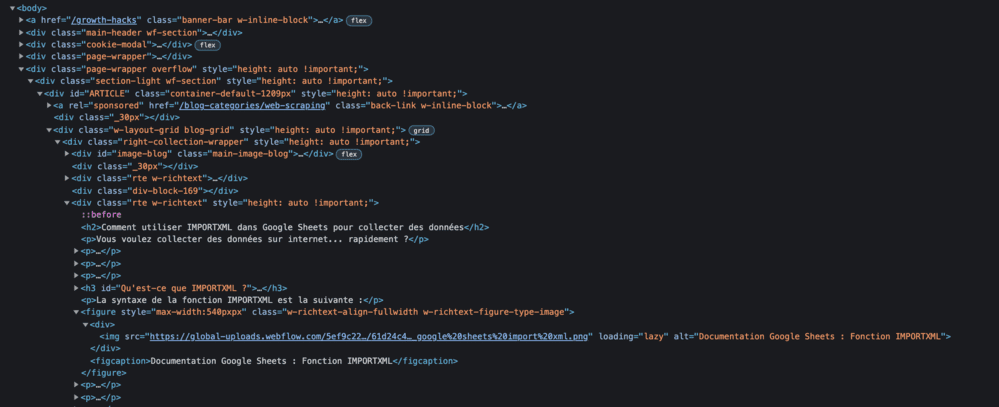
Cela ne vous parle pas ? Pas de panique, nous allons voir à l'étape ci-dessous que le plus dur à faire pour vous sera une fois de plus de faire un "clic droit"
Copier/Coller le Xpath
L'inspecteur (disponible généralement dans la rubrique des Outils de Développement de votre navigateur) vous permet de sélectionner directement la page l'élément dont vous souhaitez plus d'informations :
- Sélectionner sur la page avec l'Inspecteur la partie qui vous intéresse, c'est à dire dans cet exemple : le titre de l'un des articles
- Assurez-vous que le titre de l'article est toujours sélectionné et mis en évidence, puis cliquez à nouveau avec le bouton droit de la souris et choisissez Copier > Copier XPath.
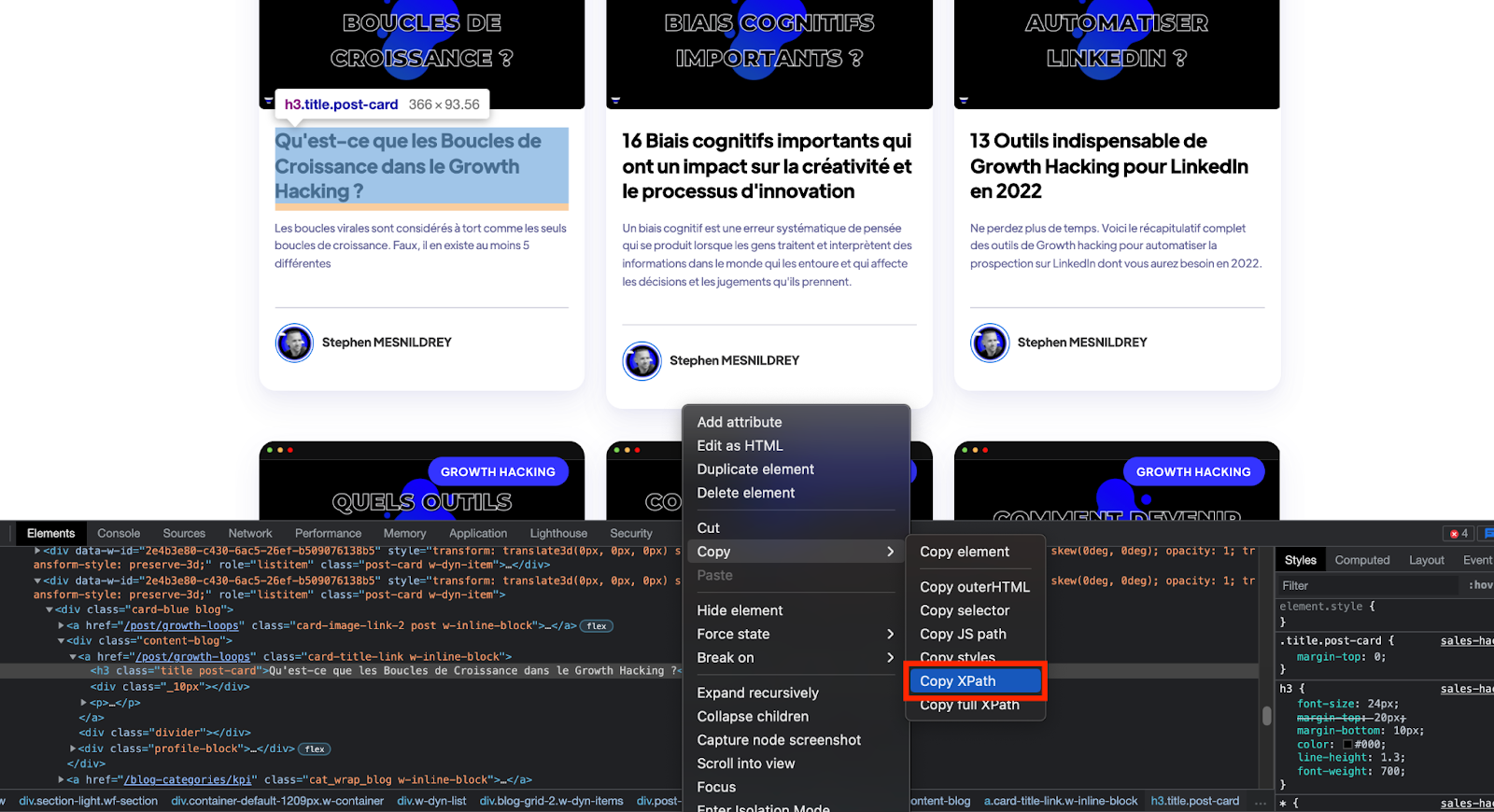
Le tour est joué, vous venez de sélectionner le XPath que vous allez utiliser tout de suite dans Google Sheets.
4. Extraire les données dans Google Sheets
Pour essayer vous même dans Google Sheets exemple, vous pouvez utiliser la feuille d'exemple ci-dessous (Créer une copie pour l'utiliser ) :
Feuille d'exemple Google Sheets : Collecte de données avec ImportXML
Note : La collecte des données des articles de blog présents dans cet article a été volontairement limité à 10 éléments pour éviter toute restriction de la part des services Google.
Récupération des articles titres de Blog
De retour dans votre document Google Sheets, introduisez la fonction IMPORTXML comme suit :
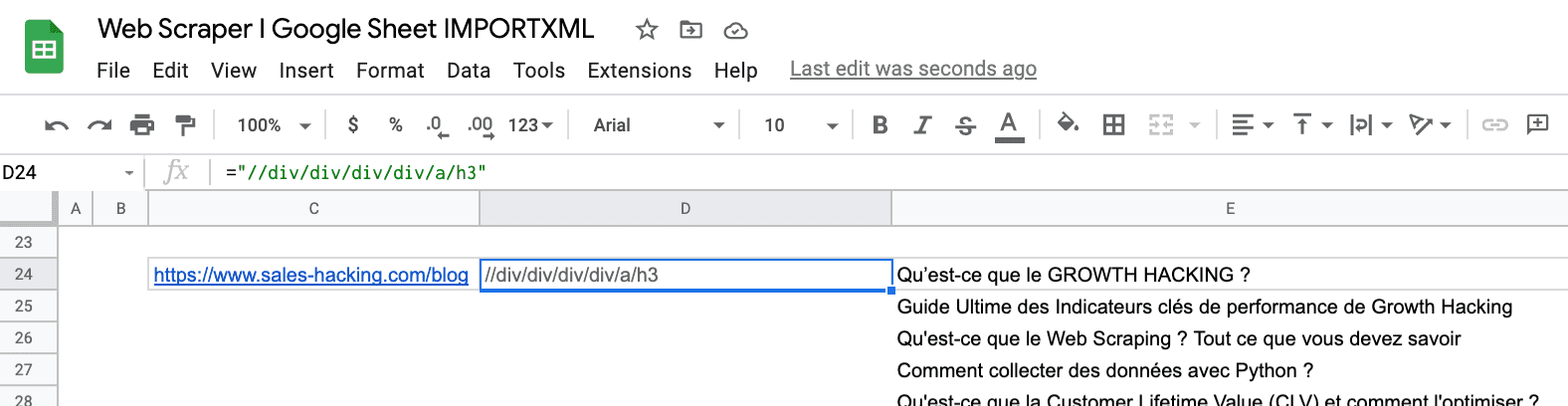
Il est possible de récupérer également les données par le biais de XPath spécifiques dans Google Sheets.
Par exemple dans l'étape 3, nous avons sélectionné le XPath d'un article spécifique qui est celui-ci :
=IMPORTXML(B1,"/html/body/div[3]/div[1]/div[2]/div[3]/div/div["&B3&"]/div/div/a/h3")

Tout d'abord, dans notre formule, nous avons remplacé l'URL de la page par la référence à la cellule où est stockée l'URL.
Deuxièmement, lorsque vous copiez le XPath, il sera toujours placé entre guillemets.
Récupération des URL des articles de Blog
Voici à quoi cela ressemble sur le document Google Sheets
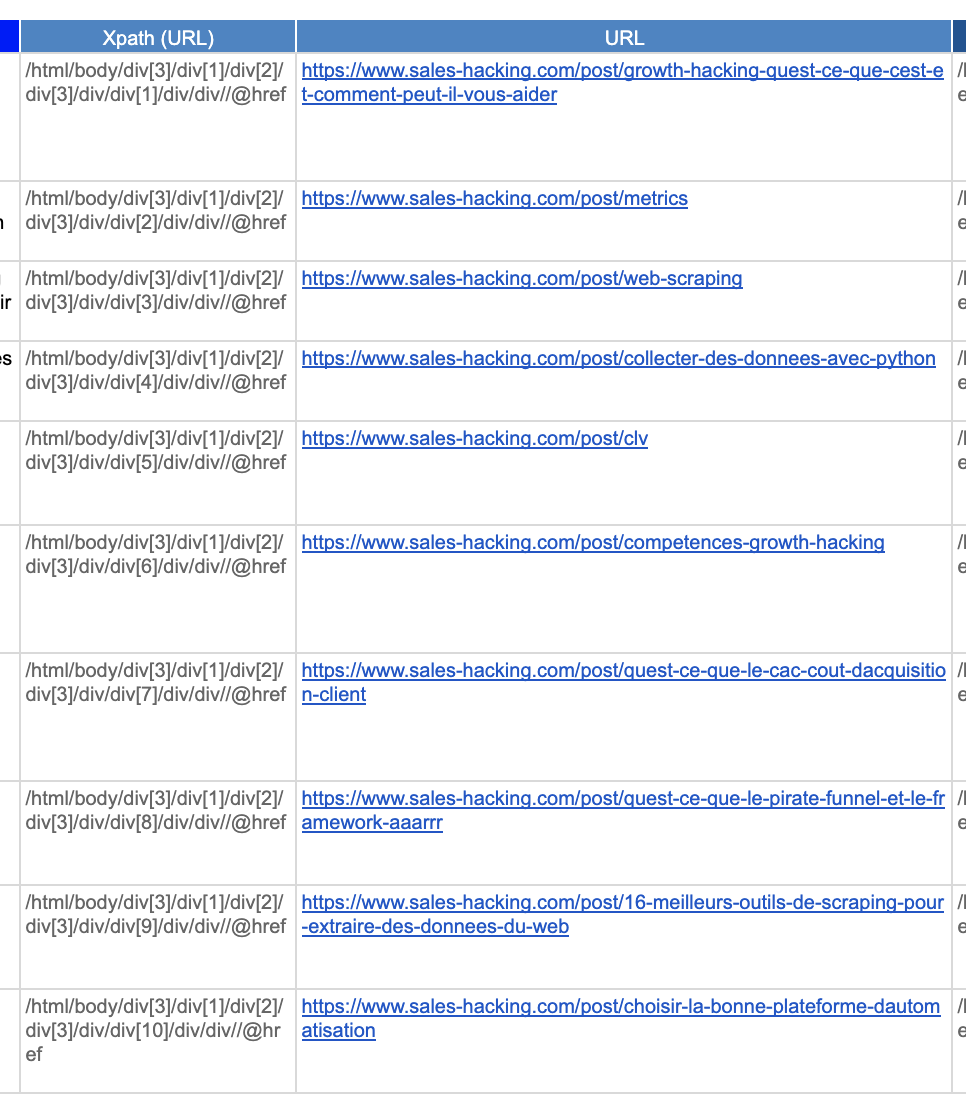
Comme vous pouvez le voir, la liste renvoie tous les articles et les URLS qui figurent sur la page que nous venons d'extraire.
Vous pouvez également appliquer ce principe à l'extraction de tout autre élément d'information nécessaire à la mise en place de vos projets comme la récupération des meta descriptions de chaque page avec Google Sheets (exemple à retrouver dans le fichier ci-dessous) :

Exemples d'utilisation d'IMPORTXML dans Google Sheets
L'exploitation d'IMPORTXML devient particulièrement puissante lorsqu'on maîtrise sa syntaxe XPath. Voici des cas d'usage pratiques pour mieux comprendre son fonctionnement.
Pour extraire les titres d'un article Wikipedia, la formule est simple mais efficace :
=IMPORTXML(A2,"//h2")
Où A2 contient l'URL de l'article. Cette commande cible spécifiquement les balises <h2> de la page.
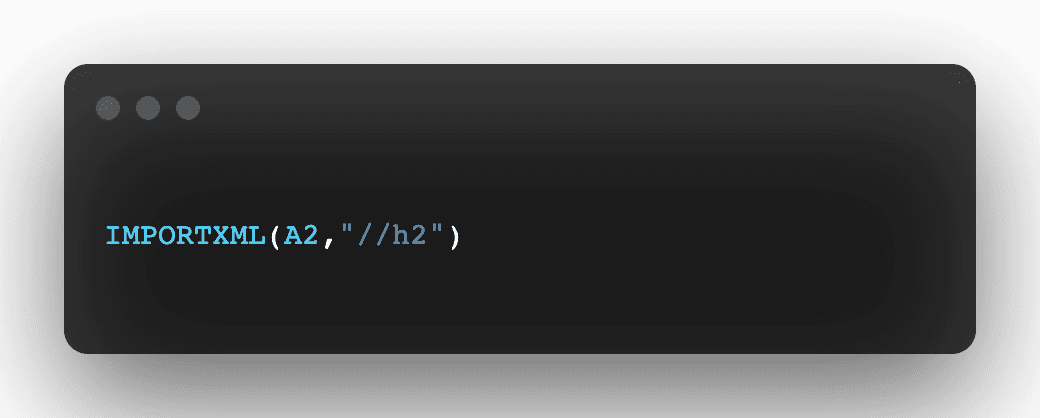
Pour des extractions plus complexes, comme les vidéos YouTube d'une page, la syntaxe s'adapte :
=IMPORTXML(A2,"//iframe/@src")

Cette formule cible les attributs src des balises <iframe>, permettant de récupérer les liens des vidéos intégrées.
Les requêtes peuvent également utiliser des fonctions avancées comme "contains" pour un ciblage précis :
- Références Wikipedia :
//li[contains(@id, 'cite_note')] - Métadonnées :
//meta/@content - Prix produits :
//span[@class='price'] - Descriptions :
//div[@class='description']

IMPORTXML permet ainsi d'extraire de nombreux types de données :
- Informations de contact
- Horaires d'ouverture
- Taux de change
- Prix et descriptions
- Données de mise en forme
Le temps de chargement varie selon le volume de données, mais reste toujours plus efficace qu'une extraction manuelle. L'important est d'identifier correctement les balises HTML ciblées dans le code source de la page.
Erreurs courantes de la fonction IMPORTXML
IMPORTXML peut générer diverses erreurs qui ralentissent vos extractions de données. Notre analyse détaillée vous guide à travers les solutions les plus efficaces.
Impossibilité de récupérer l'URL
Cette erreur frustante survient généralement à cause d'une mauvaise configuration de l'URL ou des protections du site cible. L'expérience montre que deux facteurs principaux entrent en jeu : le formatage de l'URL et les restrictions d'accès.
- Structure complète : Vérifiez la présence du protocole https:// ou http://
- Accessibilité publique : Assurez-vous que la page ne nécessite pas d'authentification
- Validation technique : Testez avec cURL ou Postman avant l'extraction
- Protection CAPTCHA : Identifiez les mécanismes anti-bot du site
- Pare-feu : Vérifiez les restrictions géographiques possibles
La vérification systématique de ces éléments permet d'éviter 90% des erreurs d'accès URL.
Contenu importé vide ou incomplet
Le contenu dynamique représente le défi majeur d'IMPORTXML. Les sites modernes utilisent souvent JavaScript pour charger leurs données, ce qui complique l'extraction.
Pour surmonter cette limitation, deux approches s'avèrent particulièrement efficaces :
- Validation du chargement : Désactivez JavaScript dans votre navigateur pour identifier le contenu statique
- Solutions alternatives : Utilisez des outils comme Puppeteer pour le contenu dynamique
L'analyse préalable du type de contenu permet d'adapter votre stratégie d'extraction et d'éviter les imports vides.
Erreurs de syntaxe XPath
La maîtrise de la syntaxe XPath conditionne le succès de vos extractions. Le code source HTML de la page constitue votre guide principal pour construire des requêtes précises.
Les tests révèlent que les meilleurs résultats s'obtiennent en suivant une approche structurée :
- Inspection du code : Analysez la structure HTML avec les outils développeur
- Test des sélecteurs : Validez vos requêtes avec XPath Helper
- Simplification : Privilégiez les chemins directs aux sélections complexes
- Documentation : Notez les sélecteurs efficaces pour réutilisation
L'optimisation constante de vos requêtes XPath garantit une extraction fiable et pérenne.
Optimisation des performances
La gestion des limites techniques de Google Sheets demande une approche stratégique. Les analyses montrent qu'une feuille de calcul peut gérer efficacement jusqu'à 50 formules IMPORTXML simultanées.
Pour maintenir des performances optimales :
- Consolidation : Regroupez les extractions similaires
- Automatisation : Utilisez Google Apps Script pour les tâches volumineuses
- Distribution : Répartissez les extractions sur plusieurs feuilles
- Planification : Échelonnez les mises à jour automatiques
- Maintenance : Nettoyez régulièrement les données obsolètes
Une gestion rigoureuse des ressources permet d'exploiter pleinement le potentiel d'IMPORTXML tout en maintenant des performances optimales.
Différence entre IMPORTFEED et IMPORTXML dans Google Sheets
Lorsqu'il s'agit de récupérer des données à partir du web dans Google Sheets, les fonctions IMPORTFEED et IMPORTXML offrent des options puissantes, mais elles s'appliquent à des cas d'utilisation spécifiques. Voici un tableau comparatif pour clarifier leurs différences et leurs applications respectives :
En résumé :
- Utilisez IMPORTFEED pour automatiser la récupération des articles ou mises à jour depuis un flux RSS ou Atom.
- Optez pour IMPORTXML si vous devez extraire des données précises comme des tableaux, des listes, ou des informations spécifiques d'une page web.
FAQs
Comment puis-je automatiser le processus de collecte de données avec IMPORTXML dans Google Sheets ?
Vous pouvez automatiser le processus de collecte de données en utilisant des scripts Google Apps ou des outils de programmation tiers tels que Python.
Les scripts peuvent être utilisés pour définir un calendrier de collecte de données, ajouter des données extraites à une feuille de calcul et envoyer des notifications de mise à jour.
Y a-t-il des limites à l'utilisation de IMPORTXML dans Google Sheets ?
Oui, il y a des limites à l'utilisation de IMPORTXML dans Google Sheets.
Par exemple, certains sites peuvent bloquer l'accès à leurs données, ou les données peuvent ne pas être structurées de manière à ce qu'elles puissent être facilement collectées avec IMPORTXML.
De plus, la fonction peut être ralentie si elle est utilisée pour extraire des données à partir de nombreuses pages Web en même temps.
IMPORTXML fonctionne-t-il avec tous les sites ou y a-t-il des restrictions ?
IMPORTXML fonctionne avec la plupart des sites, mais il peut y avoir des restrictions sur certains sites.
Les sites qui utilisent des technologies de protection avancées telles que les captchas ou les blocages d'IP peuvent empêcher IMPORTXML de récupérer les données. Cependant, dans la plupart des cas, IMPORTXML fonctionne bien pour extraire des données.
Conclusion

Comme vous pouvez le constater, IMPORTXML de Google Sheets peut être une fonction très puissante dans votre arsenal.
Vous disposez ainsi d'une méthode entièrement automatisée et sans erreur pour extraire des données de (potentiellement) n'importe quelle page Web, qu'il s'agisse du contenu et des descriptions de produits ou de données e-commerce telles que le prix du produit ou les frais d'expédition.
À une époque où les informations et les données peuvent constituer l'avantage nécessaire pour obtenir des résultats supérieurs à la moyenne, la capacité de collecter des données de pages Web et du contenu structuré de manière simple et rapide peut être inestimable.
De plus, comme nous l'avons vu plus haut, IMPORTXML de Google Sheets peut contribuer à réduire les temps d'exécution et les risques d'erreur.



